LLMs - 1 [Week 8]
a guide into how embeddings, positional embeddings, tokenizer (especially bpe tokenizer) work
It is highly advised you read my earlier blogs on NLP before reading this.
Introduction
You must have used ChatGPT for all your work, but how do you make your own ChatGPT? These are what we call large language models (LLMs).
An LLM is a neural network designed to understand, generate, and respond to human-
like text. These models are deep neural networks trained on massive amounts of text
data, sometimes encompassing large portions of the entire publicly available text on
the internet.
We are going to study LLMs in detail in over 4 blogs now. Below, you can see how an LLM is built and we get a working prototype of any LLM you want to build for your own purpose!
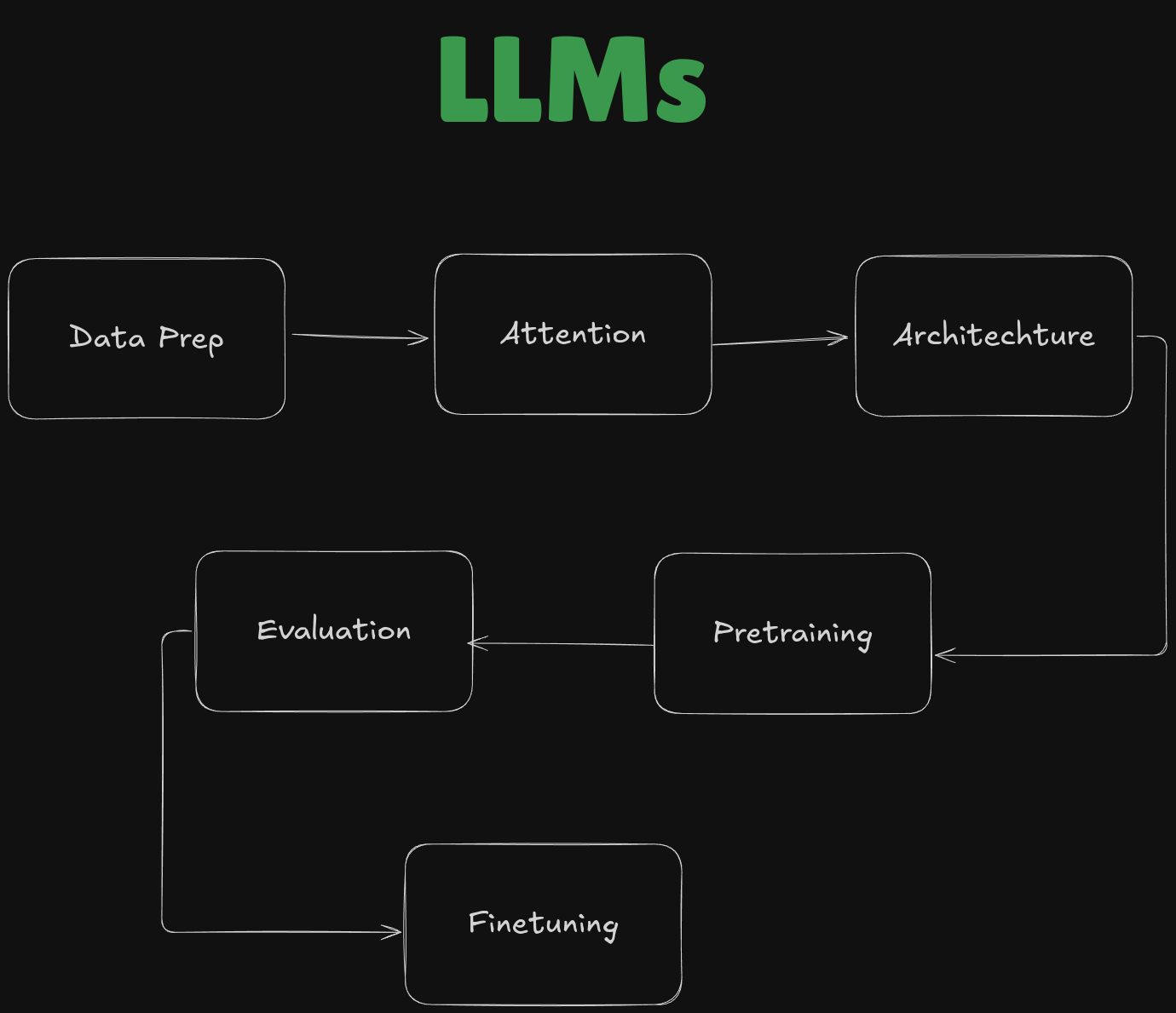
In this blog, we are going to cover the data preparation part only! It will be divided in 6 parts :
- Word Embeddings
- Tokenization
- Build a BPE Tokenizer from Scratch
- Input-Target for Training
- Token Embeddings
- Positional Embeddings
Word Embeddings
The model can’t understand any input we give. Whatever form it is in, we must convert it into some vector for the model to understand it. By this process, we do embedding!

In the case of text, we have architectures, which do this seamlessly! We have already discussed in detail about this earlier in my older blog - Basics of NLP - 1 [Week 5]
Please check it out to learn more details about word embeddings!
Tokenization
Here we will learn how to divide a corpus into individual tokens, these might be special characters or words in general
We will be using a text file (shakespeare.txt), find it here - github.com
Creating the Tokens
Let’s first open the file and see how it looks.
with open("shakespeare.txt", "r", encoding="utf-8") as f:
raw_text = f.read()
print("Total number of characters:", len(raw_text))
print(raw_text[:99])Output
Total number of characters: 6446
From fairest creatures we desire increase,
That thereby beauty's rose might never die,
But as
Now we must try to split it into tokens
preprocessed = re.split(r'([,.:;?_!"()\']|\s)', raw_text)
preprocessed = [item.strip() for item in preprocessed if item.strip()]
print(preprocessed[:40])Explanation for the Regex
Output
['From', 'fairest', 'creatures', 'we', 'desire', 'increase', ',', 'That', 'thereby', 'beauty', "'", 's', 'rose', 'might', 'never', 'die', ',', 'But', 'as', 'the', 'riper', 'should', 'by', 'time', 'decease', ',', 'His', 'tender', 'heir', 'might', 'bear', 'his', 'memory', ':', 'But', 'thou', 'contracted', 'to', 'thine', 'own']
We can see they have been tokenized into individual elements!
Create a Vocabulary
We need to create a mapping of the unique strings we got to some integers now. So that we can use those numbers instead of the strings to denote words in sentences.
words=sorted(set(preprocessed))
print(len(words))Output
544
So we have 544 unique words in the corpus. Now let’s try to make a dictionary where every integer is mapped to a unique word.
vocab={token:i for i,token in enumerate(words)}We have now created such a dictionary! Let’s see what the first 10 words are
for i,j in enumerate(vocab.items()):
print(j)
if(i>9):
breakOutput
("'", 0)
('(', 1)
(')', 2)
(',', 3)
('.', 4)
(':', 5)
(';', 6)
('?', 7)
('A', 8)
('Ah', 9)
('And', 10)
Looks like we achieved our goal!
Create a Tokenizer
Let’s revisit what it should be able to do
- Have a vocabulary
- Have an encoding function [ text to tokens ]
- Have a decoding function [ tokens to text ]
Before we make a tokenizer, we have to keep in mind some of the words might not be in the vocabulary. Hence we should add a special token for them called <|unk|>.
words.extend(["<|unk|>"])
vocab={token:i for i,token in enumerate(words)}
print(len(words))Output
545
As we see, we have added two new tokens, thus increasing the size of the set to 545!
Now, finally, let’s build the tokenizer
class Tokenizer:
def __init__(self, vocab):
self.str_to_int = vocab
self.int_to_str = { i:s for s,i in vocab.items()}
def encode(self, text):
preprocessed = re.split(r'([,.:;?_!"()\']|--|\s)', text)
preprocessed = [item.strip() for item in preprocessed if item.strip()]
preprocessed = [item if item in self.str_to_int else '<|unk|>' for item in preprocessed]
token_ids=[self.str_to_int[s] for s in preprocessed]
return token_ids
def decode(self, token_ids):
tokens=[self.int_to_str[i] for i in token_ids]
return tokensIn detail,
- str_to_int stores the vocabulary.
- int_to_str stores the inverse vocabulary, mapping strings to integers.
- Under encode,
We first break the text into tokens(like earlier). If any item is not available in the vocab, we assign a
<|unk|>token to it. Finally, we make a list of token_ids and return it in - Under decode,
We just use the inverse vocabulary, to make the sentence back from its tokens
Let’s test it out on some sample data!
text='Hello how are thee my lad'
textOutput
Hello how are thee my lad
tokenizer=Tokenizer(vocab)
print(tokenizer.encode(text))Output
[545, 268, 102, 458, 336, 545]
We see that we have successfully encoded the text, let’s try to decode it now.
print(tokenizer.decode(tokenizer.encode(text)))Output
['<|unk|>', 'how', 'are', 'thee', 'my', '<|unk|>']
Let’s go! We got back the words. But since, Hello and lad aren’t in the vocab, they get replaced by <|unk|>
But this is a very rudimentary form of tokenization. Let’s delve deep into a tokenization scheme which GPT uses itself - Byte Pair Encoding.
BPE Tokenizer
Byte Pair Encoding, commonly abbreviated as BPE, is a subword tokenization algorithm that originally found its application in data compression schemes.
The algorithm underlying BPE breaks down words that aren’t in its predefined vocabulary into smaller subword units or even individual characters, enabling it to handle out-of-vocabulary words. Hence, even non-sense words can be used as tokens in a BPE tokenizer!
Let’s build one now!
How to make it?
We develop a method to identify the most frequent pairs of adjacent characters, which guides our merging process. By iteratively merging these pairs until reaching the desired vocabulary size, we update our splits accordingly. Finally, we implement a tokenization method that applies the learned merges to new text inputs, allowing us to convert words into subword tokens effectively.
Step 1
First, we need to create a class that will handle our BPE tokenizer. This class will store the corpus, vocabulary size, frequencies of words, and many more.
from collections import Counter
class BPE:
def __init__(self, corpus, vocab_size, max_iter=None):
self.corpus = corpus
self.vocab_size = vocab_size
self.word_freq = Counter()
self.splits = {}
self.merges = {}
self.max_iter = max_iterStep 2
Next, we need to count the frequency of each word in the corpus.
def train(self):
for document in self.corpus:
words = document.split()
self.word_freq += Counter(words)
for word in self.word_freq:
self.splits[word] = list(word) + ['</w>']Each word is split into its constituent characters plus an end-of-word token (</w>). This helps distinguish between different words during tokenization.