how do i train translation models on low-resource languages?
a guide into how to train translation models on low-resource languages
short blog here. just will discuss how i setup my pipeline to get models better on low resource languages. most of these were from experiences i learnt during random experiments
problem statement
let’s consider nepali, i dub it as a low resource language as it is in devanagiri script, hence models can usually confuse between them. while hindi has complex gendered nouns and foreign influences, nepali has a simpler, generally non-gendered system, different pronunciation, and unique grammatical structures.
some examples below —

which base model to choose
start from a very good multilingual model which can’t do nepali, but is trained on a considerable amount of devanagiri text.
for example use models like sarvamai/sarvam-translate · Hugging Face or ai4bharat/indictrans2-indic-indic-1B · Hugging Face
lora or full finetune?
usually you will be constrained on gpu resources (i guess), so please use lora finetuning.
my suggestion would be to take the lora rank should be half of the lora alpha (at least), the logic i use for this is below —

paper for the above excerpt - arxiv.org
where to get the data?
case 1 : internet has digitalized data
go to huggingface and search by language
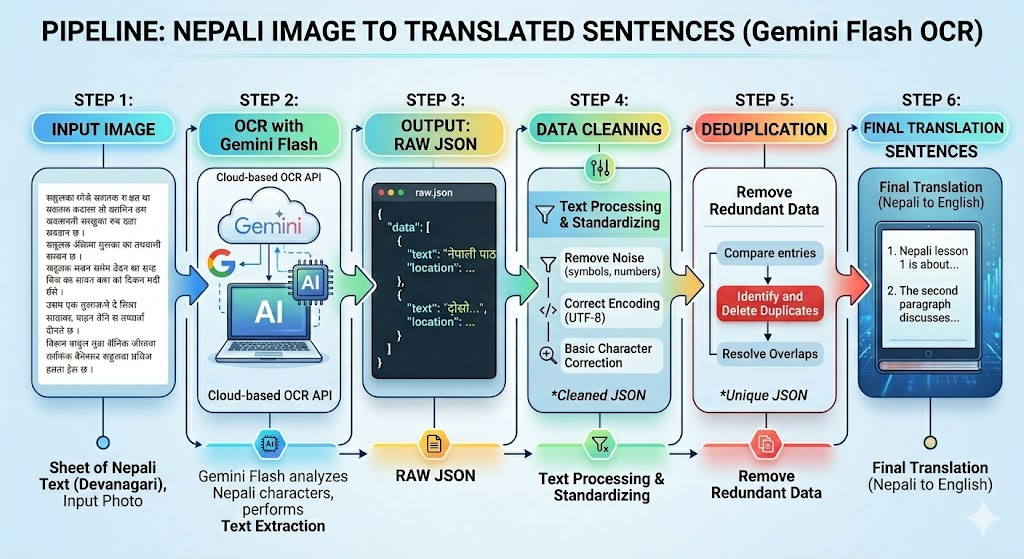
case 2 : image data exists but not digitalized
this is devanagiri text at the end of the day, so we can easily ocr it!
pull up gemini flash and chunk your image data to 10-15 pages [ i found it best at this page length ]
tell it to output the result in a json like [nepali : {}, english:{}]
and you get the final output after a bit of cleaning
extension for case 2 : where do I get data for my ocr
we should think in 3 levels : word level, sentence level and document level
document level is very tough to solve even for good resource languages, so let’s avoid that
for word level
the best source of data is english-nepali dictionaries. you can scrape them and get accurate translations for nepali at word level
for sentence level
two ways to go about this —
- train the model on the word level data, and chunk the sentences into words and then translate the sentences into nepali. the problem is these sentences wont have good context retention and many a times the sentences dont make much sense — use this method for very very very low resource languages
- court judgements are good source, as many countries do run translations for court judgements. many folklore books in nepali will have english translations, get the data parallely for both of them. there are many many sources — you just have to find em
how do i finetune?
best way is to use unsloth for finetuning — Unsloth Notebooks | Unsloth Documentation
hop on any of their notebooks and finetune the model
the hyperparams i find best for MT are as follows —
from trl import SFTConfig, SFTTrainer
trainer = SFTTrainer(
model = model,
tokenizer = tokenizer,
train_dataset = dataset,
args = SFTConfig(
per_device_train_batch_size = 4,
gradient_accumulation_steps = 16,
warmup_steps = 5,
# num_train_epochs = 1, # Set this for 1 full training run.
max_steps = 1000,
learning_rate = 3e-5,
logging_steps = 1,
optim = "adamw_8bit",
weight_decay = 0.001,
lr_scheduler_type = "linear",
seed = 42,
output_dir = "outputs",
report_to = "wandb", # Use TrackIO/WandB etc
),
)any instruction/system prompt?
the best system prompt that has given me the best results day after day is the translate gemma ( arxiv.org) system prompt
You are a professional {source_lang} ({src_lang_code}) to {target_lang}
({tgt_lang_code}) translator. Your goal is to accurately convey the meaning and
nuances of the original {source_lang} text while adhering to {target_lang} grammar,
vocabulary, and cultural sensitivities. Produce only the {target_lang}
translation, without any additional explanations or commentary. Please translate
the following {source_lang} text into {target_lang}:\n\n\n{text} in some cases, just using this gave me a boost of 5-6 chrf.
how do i evaluate?
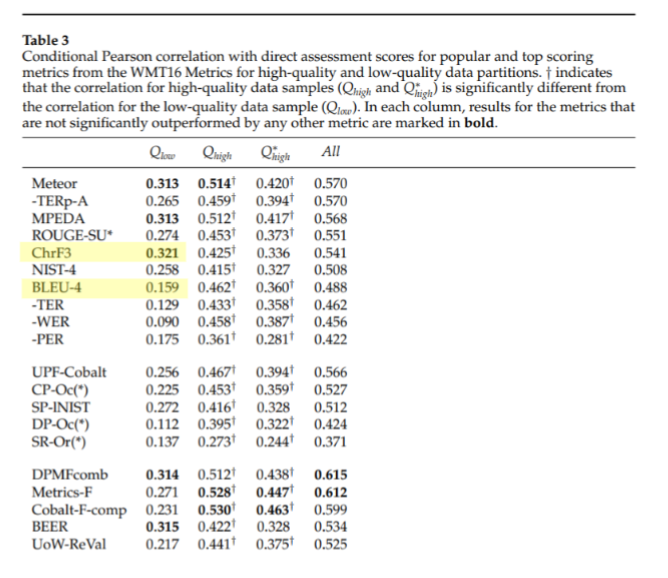
which metric do i evaluate on? i found chrf to be the best metric for low resource languages. this paper ( Taking MT Evaluation Metrics to Extremes: Beyond Correlation with Human Judgments ) validated that as well.
let’s talk about some innovative techniques
iterative backtranslation
paper to read — Iterative Back-Translation for Neural Machine Translation
the logic is simple
- train weak en ↔ nepali model.
- translate large monolingual nepali corpus → synthetic english.
- train english → nepali on synthetic pairs.
- re-translate.
- repeat.
each round improves quality.
why does it work? better MT means better synthetic data and hence again better MT
this bootstrapping loop is really good!
variation for iterative backtranslation
instead of blindly using synthetic pairs, score translations using:
- lm perplexity
- round-trip consistency
- language id confidence
this prevents noise explosion in early rounds.
how do i get better synthetic data?
paper to read — openaccess.thecvf.com
idea
train two separate models: model a and model b
generate synthetic data from both.
keep only examples where:
this ensures synthetic data stability.
cross lingual consistency regularization for synthetic data
paper to read — Unsupervised Data Augmentation for Consistency Training
idea
for each sentence:
- original lr sentence
- backtranslated lr sentence
- paraphrased lr sentence
force embedding similarity:
you make the model invariant to synthetic noise. it forces the embeddings of semantically equivalent sentences to be close.
curriculum learning
good survey paper — Curriculum Learning: A Survey
idea
rank samples by:
- sentence length
- perplexity
- morphological complexity
- noise score
train in stages: easy sentences then medium then hard
this reduces early instability.
cycledistill
paper to read — CycleDistill: Bootstrapping Machine Translation using LLMs with...
idea
- start with a large language model (llm) capable of few-shot translation.
- use it to generate synthetic parallel corpora from monolingual text (e.g., lr language → english).
- fine-tune the model on that synthetic parallel data.
- repeat the cycle: generate more synthetic data using the updated model, then refine again.
- optionally leverage softmax activations (soft target distributions) during distillation to improve performance.
final words
innovate. all the ideas above are just some examples. you must look at the problem and innovate solutions! sometimes even use 2-3 methods together. you don’t know what would work :)